Regular Expressions and Onigmo, the Ruby regular expression engine

Regular expressions (regex), are powerful tools for finding and manipulating patterns in text. They are widely used in programming languages and text editors, though they are often treated as a black box. I always considered them one part programming and one part magic. The internet is full of articles about how regex are used, but very few diving deeply into their implementations. Today we will explore the theory behind regular expressions, including a brief tour of the most basic theory. We will also delve into the implementation of the Onigmo regular expression engine, which is used in the Ruby programming language.
Brief Theory #
I learned some of the theory behind regular expressions reading “Engineering a Compiler” (Cooper & Torczon).
Regular expressions are a type of recognizer. Recognizer is a type of Finite State Automata (FA) which focuses on either accepting or rejecting a state. Here are the parts that makeup FA.
- Set of states
- Set of characters in the automation’s alphabet
- Set of directed edges between those states
- Start State
- Set of acceptance states (which can also be the start state)
The easiest way to understand and visualize the parts of a Finite State Machine is as a directed graph. dot by graphviz provides a nice way to generate these graphs.
We can create a recognizer for the word “color” that looks like this:

The recognizer starts at state 0 and is only ever in one state at a time. The recognizer moves through transitions when the next character matches the character above that arrow. This is called a state transition and is how FA do computation.
Later we could modify this state machine to accommodate alternative spellings like “colour”. The regular expression for this would be /colou?r/.

In the process we introduced a transition on ε (epsilon), a special character which is always accepted. Think of it like a “free move” in a board game. That means that on State 4 you can go to either state 5 or 7. This is the non-deterministic part of this Finite Automata (NFA). The recognizer needs to try one, see if it matches then try the other if it failed.
This kind of NFA pattern is common in regular expression which allow backtracking. Backtracking allows regular expression to do powerful things and were popularized by Pearl’s very powerful regular expression engine.
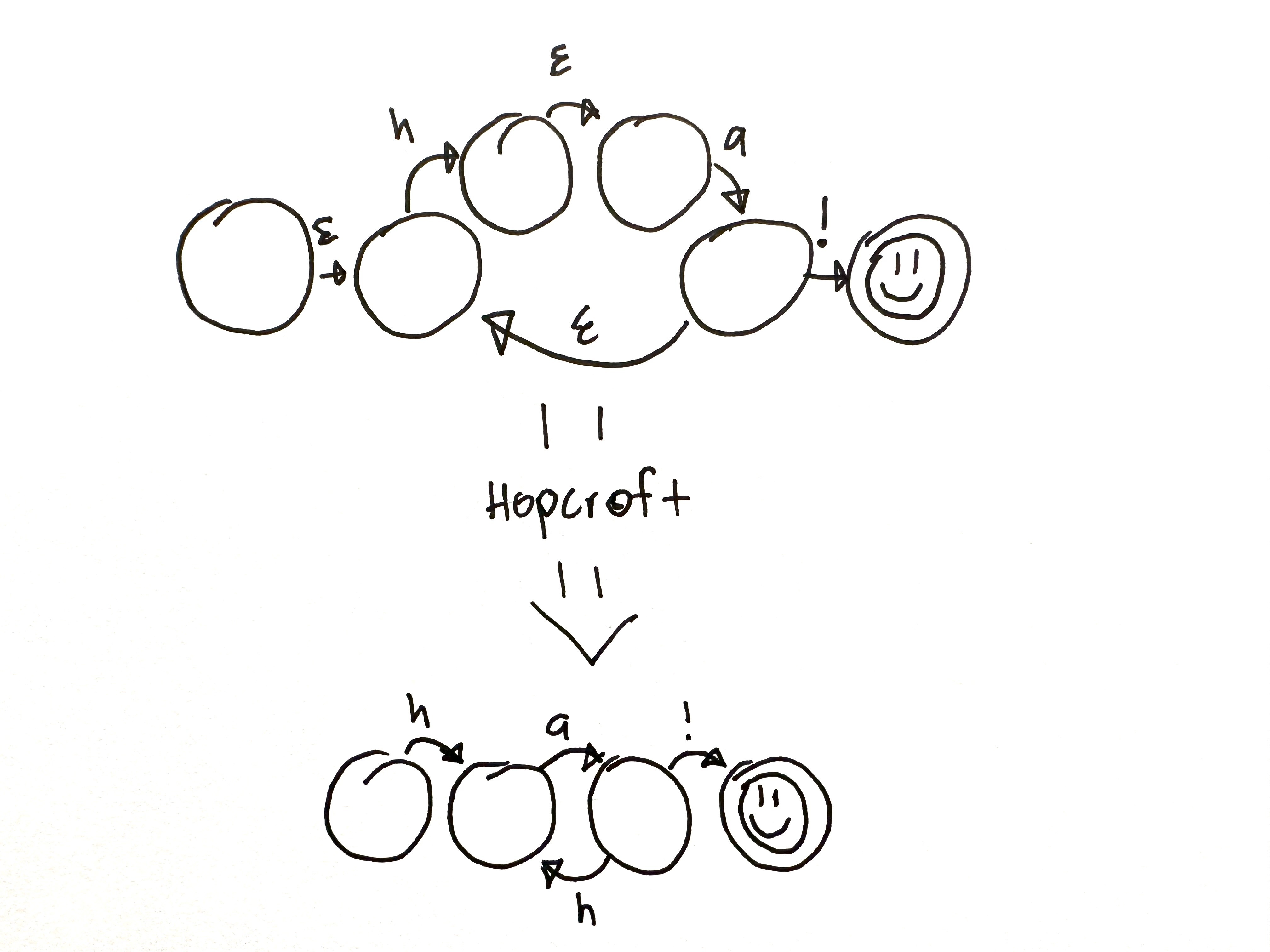
There are methods to convert NFAs into Deterministic Finite State Machines (DFA), however that is beyond the scope of this article. You can see a Ruby implementation of Hopcroft FA minimization here or learn more from the wikipedia for FA.
Onigmo #
Onigmo is a regular expression engine forked from Oniguruma that is used in the Ruby programming language. It is a powerful engine that supports a wide range of regular expression features.
What makes Onigmo work? Turns out Onigmo is a bytecode compiler similar to the Ruby VM itself. It parses the string into a series of tokens. Those tokens are consumed by the parser to create an Abstract Syntax Tree (AST) which is then converted into bytecode.
Parsing #
The regular expression string is converted into a series of one of 27 token types. These tokens are used by the parser to build an AST using one of the 11 node types.
The example regex ab?c goes through the following steps,
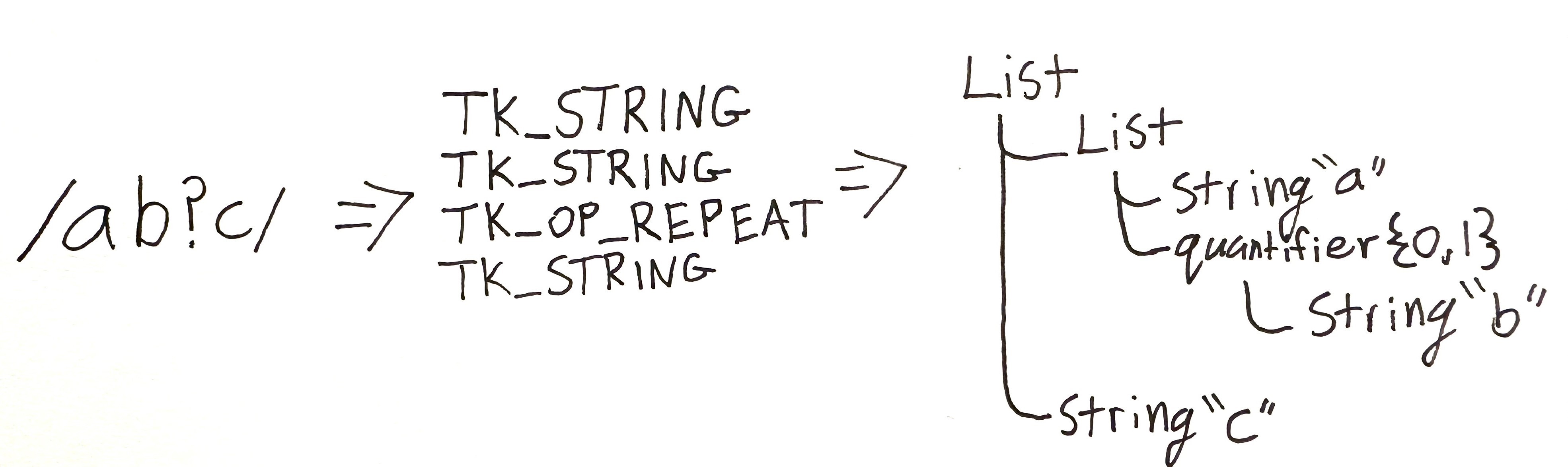
Onigmo takes these tokens and builds an AST to use when generating bytecode. This takes the linear list of tokens and gives them the appropriate hierarchical relationship.
Interestingly, despite all the theory, there is no explicit NFA or DFA structure before Onigmo starts code generation.
Compiling #
There are 97 bytecode operations. Out of those, here are 30 opcodes that are enough to get an idea of what common instruction structures look like.
Bytecode for a regex like /^ab?c(xyz)*$/ is,
2A 02 61 3E 02 00 00 00
02 62 02 63 3E 0F 00 00
00 36 01 00 04 78 79 7A
39 01 00 3D EC FF FF FF
2B 01
And here it is with annotations showing which bytes are associated with which instructions.

All the instructions take the form of OP_CODE + ARGUMENTS. For example, in the regex above, the first byte, 0x2A is the byte representing the opcode for begin-line. begin-line takes no arguments. The next byte, 0x02 represents exact1 meaning “match exactly this one character”. The byte after that (the third byte) is the ascii value for the a character (61), which is the character exact1 will match. The instruction takes up a different amount of space in the bytecode based on what arguments it takes.
0:[begin-line]
1:[exact1:a]
3:[push:(+2)]
8:[exact1:b]
10:[exact1:c]
12:[push:(+15)]
17:[mem-start-push:1]
20:[exact3:xyz]
24:[mem-end:1]
27:[jump:(-20)]
32:[end-line]
33:[end]

Here is the NFA our theory books were talking about. Implicit in the bytecode jump and push instructions, the edges on our NFA are jump instructions and the push instructions are the paths followed when backtracking.
The graph shape is implicit in the bytecode that Onigmo generates. I was expecting an explicit “build the NFA” step in the compilation process, but in reality the graph structure we think about when treating regular expressions as Finite state automata (FA) is not valuable to tell the computer how to run a regular expression. Instead the bytecode encodes what steps the computer takes exactly as it should take them. The FA structure is a feature that the human reading understands about the system, but not an explicit construct.
Character classes #
Character classes represent a set of characters that can match with a particular set of characters. To do this match Onigmo builds a byteset. Each
bit represents a character’s presence or absence from the set.

This does some math on the character’s code to find its location in the bitset. Dividing the character code by 8, decides which byte to store the bit in. Then the specific bit is determined from the remainder of that division. Only one bit is used per character in the character class. Character classes also allow Onigmo to quickly check if a character is in the character class. Checking the bit is enabled is 2 math operations and a bit wise &.
The bytecode generated for the regex, /[A-Za-z0-9]/ with a character class looks like,
10 00 00 00 00 00 00 FF
03 FE FF FF 07 FE FF FF
07 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 01
0x10 is the op code for a character class. The next 32 bytes represent the character class. This is followed by 0x01 which is the OP_END instruction. When the character class is small, there are a lot of zero bytes. The more characters included in the character class, the more filled in bytes. However, the overall byte length is similar for all ascii matches.
Captures #
There are some additional opcodes used for capture data.
| Op Code | Arguments | Usage |
|---|---|---|
| OP_MEMORY_START_PUSH | 2 byte memory location | Used when capturing a repeating pattern. Example: /(abc)+/ |
| OP_MEMORY_START | 2 byte memory location | Used when capturing a pattern once. Example: /(abc)/ |
| OP_MEMORY_END_PUSH | 2 byte memory location | |
| OP_MEMORY_END | 2 byte memory location |
There is a REC variant of the memory operations that is used in subexpression call operations, we are going to skip these instructions.
If the group is a capture, it is wrapped in a memory start and end operation. Memory start operation saves the location in the source string where the attempted match starts. The end is stored once the memory end instruction is reached. Invalid matches have -1 as the end location indicating that the match failed.
What we know now #
Regular expressions work a bit more like a programming language virtual machine than I expected. There are a number of very specific tools Onigmo uses to improve performance, but the concepts are very usefully similar to compilers for other languages. By understanding the theory behind finite state machines and the implementation of regular expression engines like Onigmo, we can use this knowledge to improve our use of regular expressions and inform the design of other text processing tools.
Glossary of Terms #
If you go on to read the code, here are some terms that might be useful.
| Term | Definition |
|---|---|
| AST | Abstract Syntax Tree |
| CC | character class |
| DFA | Deterministic fininte state automata. Meaning each state has only one correct transition on a specific input |
| MB | multibyte |
| ML | multiline |
| IC | Ignore Case |
| NG | Not Greedy |
| NFA | Nondeterministic finite state automata. Meaning a state can have multiple edge options. |
| Quantifier | number of something |